Lock-free Concurrent Skip List
Zidong Li
Longyu Yang
SUMMARY
We are going to implement a concurrent lock-free skip list using C++ and compare its performance with skip lists implemented by coarse-grained global locks and fine-grained per-pointer locks on a multi-core CPU machine.
BACKGROUND
Skip list, illustrated by Figure 1, is a very interesting data structure for searching an element in an ordered sequence. Its probabilistic feature guarantees O(logN) time complexity for search, update, and deletion, yet its linked-list-like overall structure is much easier to implement compared to tree-like search structures such as red-black trees. As a result, skip lists are used by many modern applications. For example, the famous in-memory key-value storage Redis implements its sorted set data structure using a skip list. And the Java programming language absorbs thread-safe skip lists as a standard library called ConcurrentSkipListMap. In this project, we will first implement a global locking thread-safe version of our skip list usingC++. Next, we will build a fine-grained per-pointer locking skip list based on algorithms introduced by Pugh [1]. Finally, using the Compare-and-Swap(CAS) based algorithms proposed by Fraser [2], we will achieve our final lock-free skip list and compare its performance with our previously implemented locking versions.
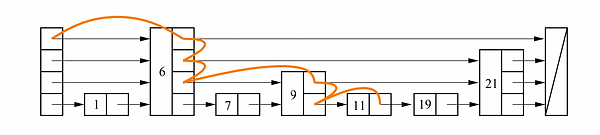
Figure 1: Illustration of searching in a skip list. Source: [2]
THE CHALLENGE
- It's difficult to verify the correctness of our code. Even though the algorithm is proved to be correct (For instance, the correctness of the per-pointer lock algorithm is proved in [1]), there is still a chance of introducing subtle bugs in terms of implementation. To ensure the quality of our code, we might refer to the empirical validation method mentioned in [2]. Specifically, we can log all concurrent operations and perform a depth-first search to find a valid serialized operation sequence. If a valid sequence can't be found, we can be sure that there are some bugs in the code.
- It's challenging to construct workloads that are able to differentiate the performance of our different implementations. To tackle this issue, we might refer to random workloads constructed in previous works, such as [2] and [3].
RESOURCES
For parallel machine resources, we will evaluate the performance on one of the 8-core GHC machines. We might also evaluate the performance on the PSC Bridges-2 RM if time allows. For code base, we will build our code from scratch using C++ and only refer to pseudo-code provided by research papers, such as [1] and [2].
GOALS AND DELIVERABLES
-
We PLAN TO achieve three versions of concurrent skip lists: global locking, fine-grained locking, and lock-free.
-
We PLAN TO empirically verify the correctness of our code and construct several workloads to evaluate the performance.
-
We PLAN TO compare the performance of three versions of our implementations to see whether the fine-grained locking version performs better than the global locking version and whether the performance can benefit more from non-blocking lock-free implementation.
-
If time allows, We HOPE TO implement a Java version of our lock-free skip list and compare it against the Java ConcurrentSkipListMap standard library.
-
At the final post-session, we PLAN TO illustrate the performance comparisons by using several graphs, each of which shows the operation throughput of those three implementations with different workloads that we construct.
-
By doing this project, we PLAN TO have a more thorough understanding of fine-grained synchronization and lock-free data structures, and what's more, how they are implemented on modern architectures.
PLATFORM CHOICE
We will start to work on our code on one of the 8-core GHC machines using C++. Compared to other high-level languages like Java, C++ can achieve better overall performance and there are also more useful tools that can help us locate subtle bugs and identify performance bottlenecks. If time allows, we might also evaluate the performance on the PSC Bridges-2 RM.
SCHEDULE
week 1 (11.1 - 11.7) Submit the project proposal, read reference papers thoroughly, and start to implement a skip list with a global lock.
week 2 (11.8 - 11.14) Work on the skip list with fine-grained locks.
week 3 (11.15 - 11.21) Test the correctness of the skip list with a global lock and the skip list with fine- grained locks. work on the project milestone report.
week 4 (11.22 - 11.28) Work on the lock-free concurrent skip list.
week 5 (11.29 - 12.6) Analyze the performance of three versions of the concurrent skip list and do benchmark tests.
week 6 (12.7 - 12.9) Finish up the project and write the final report.
Reference
[1] W. Pugh, “Concurrent maintenance of skip lists,” Department of Computer Science, University of Maryland, 06 1990.
[2] K. Fraser, “Practical lock-freedom,” PhD thesis, University of Cambridge, 01 2004.
[3] M. Herlihy, Y. Lev, V. Luchangco, and N. Shavit, “A provably correct scalable concurrent skip list,” in Conference On Principles of Distributed Systems (OPODIS). Citeseer, p. 103, Citeseer, 2006.